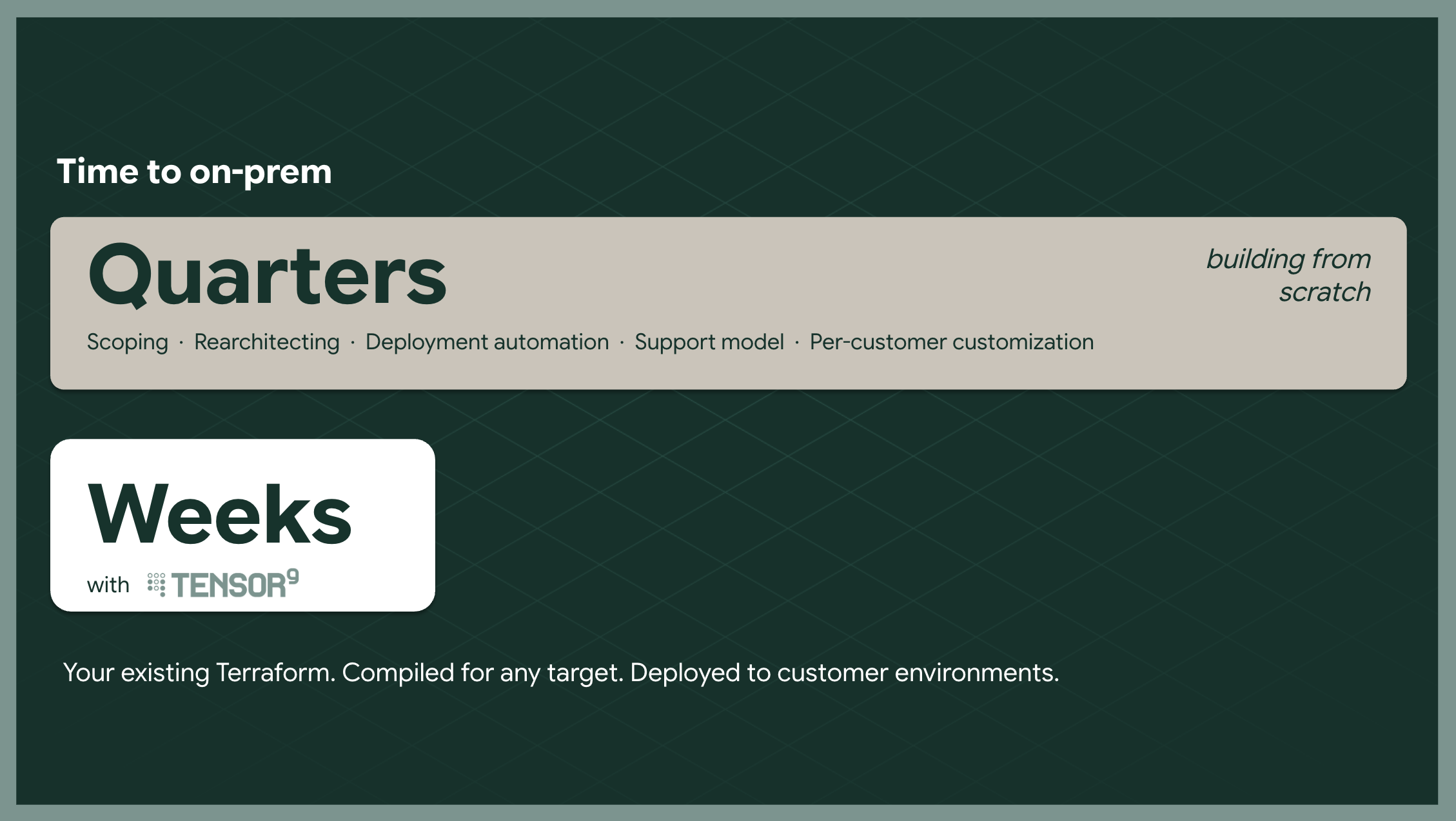
Time to Value: Why On-Prem Doesn’t Have to Take Quarters

Share this:
I’ve been watching more vendors talk openly about what it actually takes to ship software into customer environments. Two recent conversations stood out to me.
The first is an interview with Gil Feig, CTO of Merge, on Sedai’s “One Idea” show. Gil walks through Merge’s journey to customer-hosted deployments: 18 weeks for their first, eventually getting down to 4 to 6 weeks per customer, with a goal of reaching 2. He’s candid about the surprises along the way, especially how much of the work turned out to be non-engineering: support models, contractual access, pricing changes.
The second is a panel from GroundCover’s “BYOC in Practice” webinar featuring engineers from ClickHouse, Zilliz, and GroundCover. Each company took a different path to running in customer accounts, and each one describes months or years of investment to get there.
These are pioneering teams, and the industry is learning from them. Gil, Ashish, James, and Noam are all sharing hard-won operational knowledge that didn’t exist in the open a few years ago. The pattern across their experiences reinforces something we’ve believed since starting Tensor9: most of this effort is duplicated, and it doesn’t have to be.
The same problems, solved from scratch each time
Whether you call it on-prem, BYOC, single-tenant, or customer-hosted, the challenges converge. Every vendor who goes down this road hits the same set of problems.
Service dependencies. Merge depends on 16 to 18 AWS services. ClickHouse runs on EKS with a control plane that spans accounts. Zilliz deploys a full stack (vector DB, object storage, meta storage, Redis, logging, observability) entirely inside the customer’s VPC. Each team did the painstaking work of inventorying every managed service dependency and deciding what to keep, what to replace, and what to rearchitect. Merge converted their queuing to Kafka. Zilliz built a Crossplane abstraction layer for multi-cloud. These are genuine engineering contributions that the rest of the industry can learn from.
Per-customer variation. Every customer environment is different. ClickHouse keeps the UI identical between SaaS and BYOC to avoid engineering divergence, but the underlying infrastructure still varies per deployment. GroundCover supports fully air-gapped environments alongside connected ones. Merge still has Terraform drift between customers and customizes each deployment. The GroundCover panel called out Kubernetes upgrade coordination as a recurring pain point: you have to align maintenance windows with every customer individually.
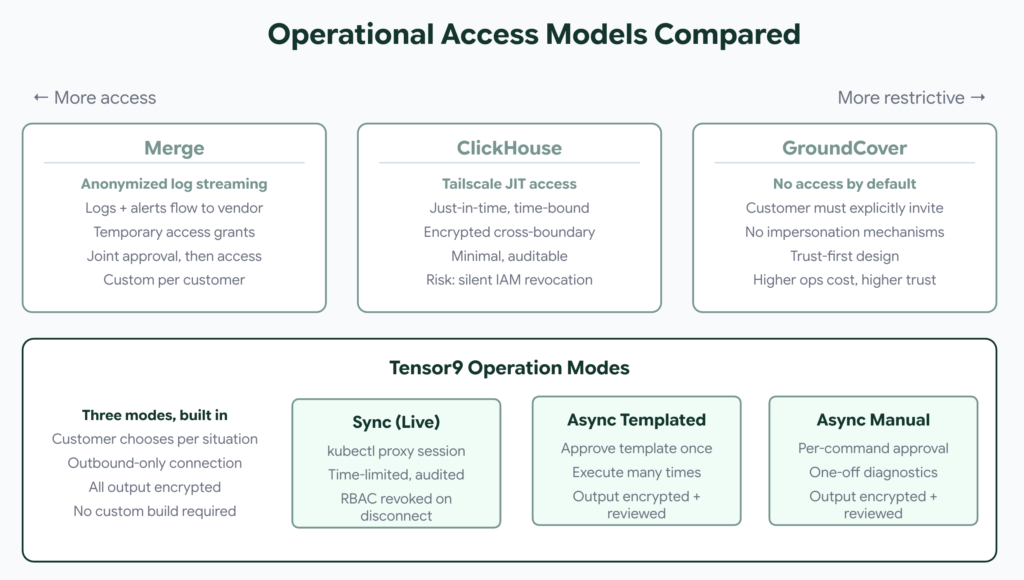
Operational access. Every vendor has to navigate the tension between security and operational access, and the approaches these teams developed are genuinely smart. Gil designed anonymized log streaming and joint approval workflows for temporary environment access. ClickHouse uses Tailscale for just-in-time, time-bound access during incidents. GroundCover took the hardest line: no access to customer data by default, no impersonation mechanisms by design. Ashish pointed out that customers can revoke IAM permissions without notifying the vendor, causing silent failures during upgrades. These are patterns that didn’t have established best practices until teams like these built them in production.
Ongoing operations. Software updates need to reach every customer. GroundCover uses Flux (GitOps) and Temporal (workflow orchestration) for deterministic, auditable deployments with gradual rollouts. Their cell-based isolation means a bad rollout affects one customer, not the whole platform. Merge handles updates more manually, which is part of why each new deployment still takes weeks. Zilliz uses Claude Code to write debugging scripts after incidents and builds a reusable library of agent scripts for future ops. Each team invents their own operational toolchain.
Why this effort compounds
Gil said something in his interview that captures the core problem, and it’s advice I think every vendor should hear: “The biggest mistake you can make when it comes to on-prem is letting your engineers decide how it should be built, because it’s not an engineering problem.” He’s right, and the fact that he’s sharing this publicly is valuable. Engineering is maybe 40% of the work. The rest is support models, contractual access, pricing restructuring, communication workflows between vendor and customer teams. And all of that has to be designed, built, and maintained per vendor.
Meanwhile the market pressure keeps growing. Confluent resisted BYOC for years due to operational pain, then eventually acquired a company with BYOC capabilities because they couldn’t ignore the demand any longer. Companies increasingly treat proprietary data as a competitive advantage and won’t let it sit in vendor environments. AI workloads are accelerating this: the data volumes make egress costs punishing, and Noam from GroundCover argued that AI-generated code makes data volume prediction “impossible,” which strains traditional SaaS pricing models.
The demand isn’t going away. The question is how much each vendor has to build to meet it.
What changes with Tensor9

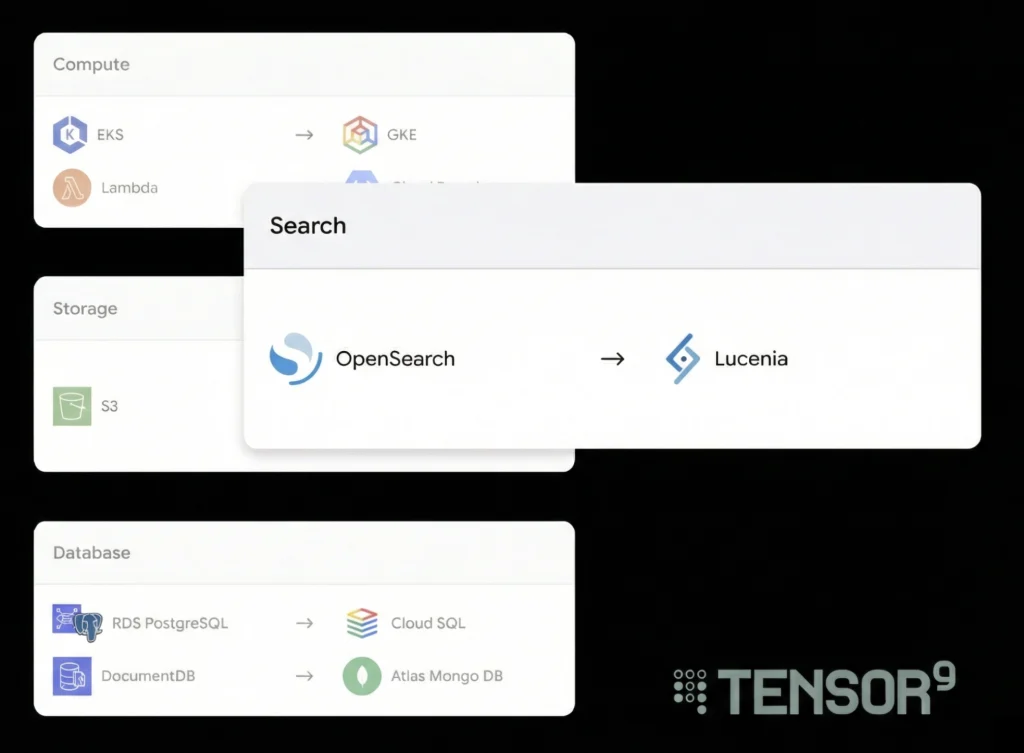
Service translation. With Tensor9, your origin stack (the Terraform you already have) gets compiled to the target environment. The service equivalents registry handles the translations: RDS to PostgreSQL on Kubernetes, S3 to MinIO, ElastiCache to self-hosted Redis. You don’t build a Crossplane abstraction layer or hand-maintain cloud-specific Terraform per customer. The compiler produces it.
Per-customer customization. Tensor9 handles environment variation with form factors: structured specifications that encode the target’s cloud, connectivity mode, security requirements, and available services. Different customer, different form factor, same origin stack.
Operational access. Tensor9 builds the operational model into the deployment. The appliance (the customer’s running instance) streams telemetry back through a secure, outbound-only channel. Beyond telemetry, vendors get three operation modes: async templated operations (customer approves a script template once, vendor executes repeatedly, every output encrypted and customer-reviewed before release), async manual operations (per-command approval for one-off diagnostics), and sync operations (live kubectl proxy for real-time debugging, time-limited, audited, RBAC revoked on disconnect). No inbound firewall ports. Application data never leaves customer infrastructure.
Updates and lifecycle. Push an update to your origin stack, recompile, and the update gets delivered through the same channel that handles initial deployment. No custom GitOps pipeline to build and maintain per vendor.
The timelines
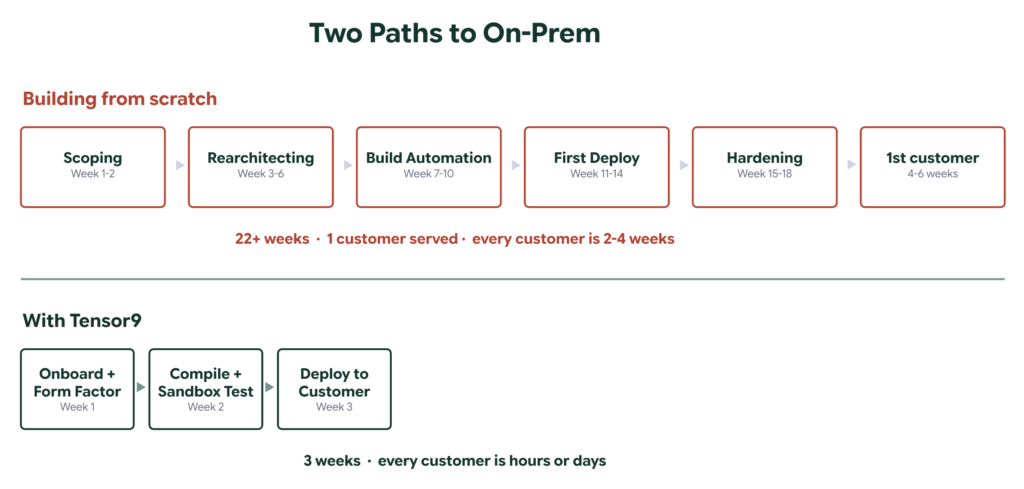
Building from scratch (representative of what the panelists described):
| Week 1-2: Scoping and service inventory |
| Week 3-6: Rearchitecting for portability |
| Week 7-10: Building deployment automation |
| Week 11-14: First customer deployment and debugging |
| Week 15-18: Hardening, support model, documentation |
| Weeks 19-25: Deploy to customer environment |
| Total: 22-25+ weeks (2-4 weeks per subsequent customer) |
With Tensor9:
| Week 1: Onboard origin stack, define form factors |
| Week 2: Compile, test deployment in sandbox |
| Week 3: Deploy to customer environment |
| Total: 3 weeks (hours or days per subsequent customer) |
Zilliz has been building their BYOC from scratch for about three years. GroundCover had the foresight to design for it from day one. Both approaches produced impressive results, and the knowledge they’re sharing is raising the bar for the whole ecosystem. The difference with Tensor9 is that the hard problems (service translation, environment parameterization, deployment automation, operational access, update delivery) have already been solved. You don’t have to spend years building what these teams built. You can benefit from the patterns they’ve proven while skipping the months of implementation.
You don’t have to design for it from day one
Gil’s advice for founders is worth taking seriously: think about on-prem from the start. Everything in Terraform, never log into the console, minimize drift, don’t bind yourself to AWS-specific primitives. Noam from GroundCover went further and built the entire company BYOC-native from inception, avoiding hyperscaler-specific services entirely for portability. Both are smart strategies that reflect real operational experience.
Both are valid strategies if you’re building it yourself. But with Tensor9 you don’t have to constrain your architecture for a future on-prem requirement. Build for your cloud, use every managed service that makes you faster. The compiler handles the translation when the enterprise deals show up. Your day-one speed doesn’t have to be sacrificed for day-500 flexibility.
If any of this sounds familiar, I’d love to chat.
We offer a focused 45-minute assessment where we sit down with your team and work through three things: your current deployment model, the operational risks and bottlenecks you’d face going on-prem, and a concrete path to delivering in enterprise customer environments without custom installs or operational sprawl. Bring your architecture and we’ll tell you what we see.
Reach out at tensor9.com or email me directly at [email protected].
—Sources referenced in this post: “The 23-Minute Playbook for On-Prem Products” featuring Gil Feig (Merge) on Sedai’s “One Idea” show, and “BYOC in Practice: Architectures, Tradeoffs, and Real-World Implementations” featuring Ashish Kohli (ClickHouse), James Luan (Zilliz), and Noam Levy (GroundCover).